在 CNN-based 的架構中,會使用三種不同的 CNN 架構:
要讓語音特徵能夠進入到 CNN 中,就必須將其轉換成圖片的維度格式。因此我們將原本384為的特徵向量 reshape 成 16x12x2 的張量(Tensor)作為 CNN 的輸入。
首先是 Basic CNN 的部份,模型包含了四層卷積層(conv),每一層的輸出特徵圖(feature map)維度皆為 40,其卷積核(kernel)大小分別為:5x5、3x3、2x2 與 1x1。每一層的卷積層後都會接上一層最大池化層(max-pooling),其pooling size 與前一層卷積層的卷積核大小相同。經過四層的卷積層與最大池化層後,我們會將特徵圖向量化(flatten)並輸入至最後的輸出層中,架構如圖 1
圖 1: CNN靜態模型。每一層卷積層後的 activation function 為 ReLU,所有卷積層的最大池化層padding 方式皆為 zero-padding,卷基層 stride=2:最大池化層 stride=1
接下來說明的是 Multi-Scale CNN。
Multi-scale CNN 的主要想法是基於如何找出近似 CNN 中的最佳局部稀疏結
構,目標是找出最佳的局部結構並在空間上重複。我們會透過使用多種不同大小卷
積核的卷積層來擷取相關的特徵(包含1x1、3x3、5x5、7x7、9x9)。Multi-scale
CNN 架構中另一個重要的部份為 max-out activation unit,max-out activation unit 的輸入為多個不
同大小卷積核的卷積層的輸出,並透過取最大值的方式來使多個卷積核相互競爭,最
後的輸出即為這些卷積層輸出中的最大值。在此機制中,會產生一個局部的控制機
制,讓非 0 的 activation value 在傳遞時只會通過網路中的其中一部份。藉由此方法,在原始的
模型架構內部建構一子網路可以使模型處理更為複雜的問題。
此部份是以 Basic CNN 基礎並加入 multi-scale 模組,模型架構如圖 2。第一層包含五種不同
大小的卷積核,分別是:1x1、3x3、5x5、7x7 與 9x9,其輸出的特徵圖維度皆為 40,接下來使用max-out unit從五個相同維度的特徵圖中挑選出最大值。第二層中,我們將前一層中最大的卷積核(9x9)移除並將輸出的特徵圖維度減為 30,一樣使用 max-out unit 從四個相同維度的特徵圖中挑選出最大值。第三及第四層以相同的模式移除前一層中最大的卷積核並將輸出的特徵圖維度減少,經過四層的多尺度卷積層後將特徵圖向量化 (Flatten) 並輸入至最後的輸出層中。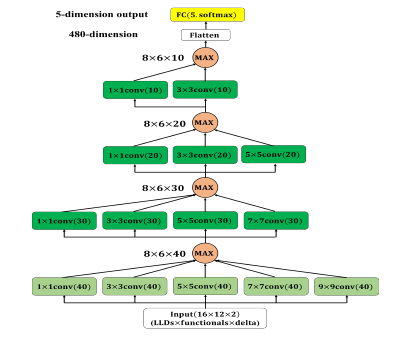
圖 2: Multi-scale CNN 靜態模型。每一層卷積層後的activation function 使用 ReLU,所有卷積層 padding 方式皆為 zero-padding,淺綠色卷積層 stride=2;深綠色卷積層 stride=1
程式的部分如下
cnn_train_data = np.reshape(train_data, (train_data.shape[0], args.llds, args.functionals, args.delta))
cnn_test_data = np.reshape(test_data, (test_data.shape[0], args.llds, args.functionals, args.delta))
# 8x6x40
conv1_1 = Conv2D(filters=40,kernel_size=(1,1),strides=(2,2),padding='same', activation='relu', name='conv1_1')(cnn_input)
conv1_2 = Conv2D(filters=40,kernel_size=(3,3),strides=(2,2),padding='same', activation='relu', name='conv1_2')(cnn_input)
conv1_3 = Conv2D(filters=40,kernel_size=(5,5),strides=(2,2),padding='same', activation='relu', name='conv1_3')(cnn_input)
conv1_4 = Conv2D(filters=40,kernel_size=(7,7),strides=(2,2),padding='same', activation='relu', name='conv1_4')(cnn_input)
conv1_5 = Conv2D(filters=40,kernel_size=(9,9),strides=(2,2),padding='same', activation='relu', name='conv1_5')(cnn_input)
conv1_maxout = maximum([conv1_1, conv1_2, conv1_3, conv1_4, conv1_5], name='conv_max1')
#4x3x30
conv2_1 = Conv2D(filters=30,kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv2_1')(conv1_maxout)
conv2_2 = Conv2D(filters=30,kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv2_2')(conv1_maxout)
conv2_3 = Conv2D(filters=30,kernel_size=(5,5),strides=(1,1),padding='same', activation='relu', name='conv2_3')(conv1_maxout)
conv2_4 = Conv2D(filters=30,kernel_size=(7,7),strides=(1,1),padding='same', activation='relu', name='conv2_4')(conv1_maxout)
conv2_maxout = maximum([conv2_1, conv2_2, conv2_3, conv2_4], name='conv_max2')
#2x2x20
conv3_1 = Conv2D(filters=20,kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv3_1')(conv2_maxout)
conv3_2 = Conv2D(filters=20,kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv3_2')(conv2_maxout)
conv3_3 = Conv2D(filters=20,kernel_size=(5,5),strides=(1,1),padding='same', activation='relu', name='conv3_3')(conv2_maxout)
conv3_maxout = maximum([conv3_1, conv3_2, conv3_3], name='conv_max3')
#1x1x10
conv4_1 = Conv2D(filters=10, kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv4_1')(conv3_maxout)
conv4_2 = Conv2D(filters=10, kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv4_2')(conv3_maxout)
conv4_maxout = maximum([conv4_1, conv4_2], name='conv_max4')
output = Dense(units=args.classes, activation='softmax', name='output')(conv4_maxout)
model = Model(inputs=cnn_input, outputs=output)
model.summary()
明天將繼續介紹 Multi-Scale CNN with Attention Mechanism 以及比較三種模型的效果~

